Recordem que un dels processos clau en SEO és el rastreig. En aquest procés, Google envia els seus robots a analitzar el contingut del nostre lloc web. L’anàlisi de logs és, per tant, rellevant, perquè ens permet entendre quins bots de Google visiten la nostra web, amb quina freqüència, quins fitxers o pàgines consulten i quina resposta estan obtenint per part nostra. Mitjançant aquests accessos, detecten noves URLs o bé continguts modificats en pàgines que ja eren al seu índex. A més, cada web té una freqüència i un volum de rastreig limitats (crawl budget), així que ens interessa molt entendre quins fitxers visita i què hi troba quan els rastreja.
En aquest post hi trobaràs:
1. Què són els logs?
Una definició conceptual seria “un registre oficial d’esdeveniments durant un rang de temps concret que s’utilitza per registrar dades o informació sobre qui, què, quan, on i per què un esdeveniment succeeix” (
vegeu la wiki). En el cas que ens ocupa, són els
registres de visites dels robots, com els de Google, a fitxers del nostre servidor web. Aquests registres generen un fitxer de text amb totes aquestes peticions, que nosaltres després extraurem per analitzar. Als fitxers de logs hi ha peticions de molts agents, també dels usuaris, però la nostra intenció serà obtenir només aquells que ens interessen per a SEO.
Anatomia d’un registre de log
- IP: adreça a internet de l’usuari que ens consulta
- Data: moment exacte de la consulta i la seva zona horària
- Tipus de sol·licitud (GET, POST)
- URI: el recurs sol·licitat
- Protocol: HTTP1, 2 o 3
- Codi de resposta que retorna el servidor: 200, 3XX, 4XX i 5XX…
- Mida del fitxer (pes)
- User agent: quin usuari és i amb quin navegador ens consulta
En definitiva, veiem qui consulta què, a quina hora, quant pesa i què li ha tornat el nostre servidor.
Tanmateix, aquest format de logs és el més habitual per a un servidor Apache, però si fas servir un altre tipus de hosting és possible que els fitxers difereixin una mica en la seva estructura.
Com s’obtenen els registres de logs?
Tot hosting decent, amb sistemes PLESK, CPANEL o similars, hauria d’oferir-te l’opció de descarregar aquests fitxers. En cas que no ho faci, demana-ho al teu proveïdor de hosting i, de passada, vés pensant en
canviar de servidor. Una alternativa, si tens accés a FTP, és consultar des d’allà la carpeta /logs/.
2. Eines per a l’anàlisi de logs
Crawl stats de Google Search Console
La primera aproximació a l’anàlisi de logs de qualsevol SEO ha de ser aquest apartat de Search Console, que ja hem vist a la nostra
guia de Search Console.
Algunes informacions interessants que en pots obtenir són:
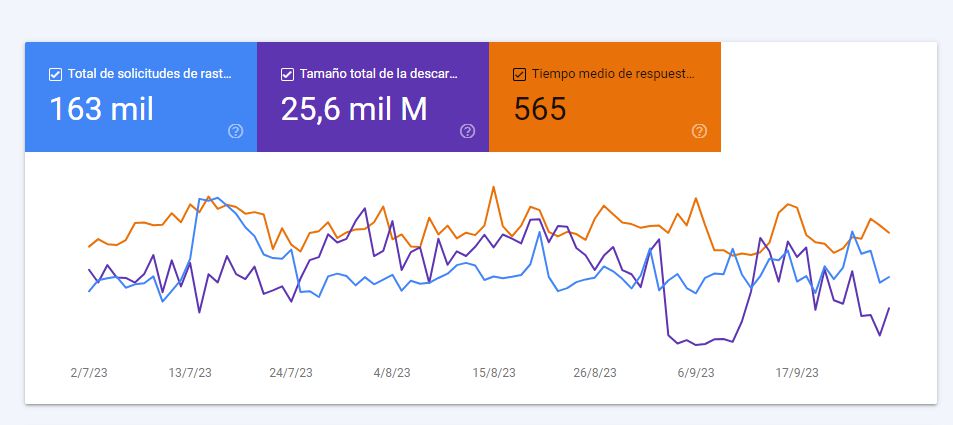
- Total de sol·licituds de rastreig (compte, només té en compte el robot que visita la teva web de forma més habitual, normalment el de smartphone)
- Mida total de la descàrrega
- Temps mitjà de resposta del servidor a la petició
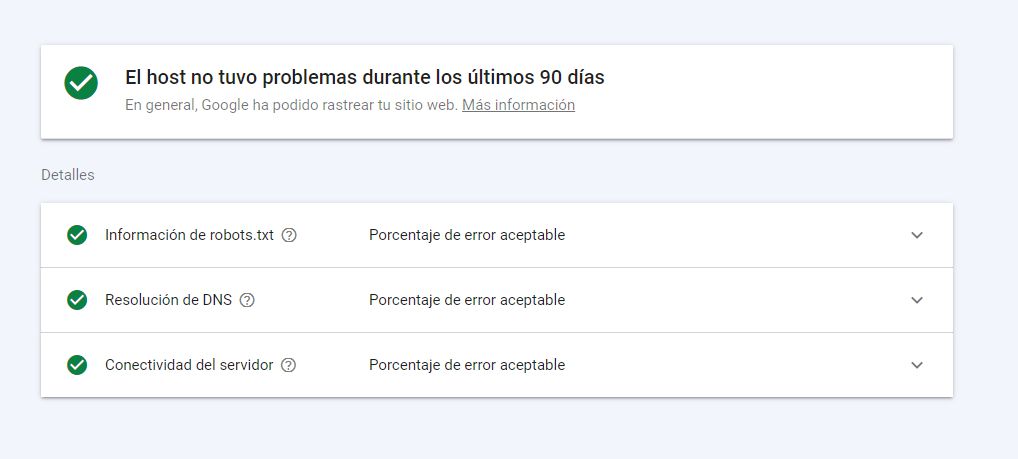
L’estat de l’host és una cosa que en un 99% dels casos estarà bé, però si no és així, estem davant d’un escenari greu: Google no ha pogut consultar la nostra web en més d’una ocasió i haurem de prendre mesures. Sempre hi ha un percentatge d’error, però no hauríem de superar mai el llindar d’error que es considera acceptable.
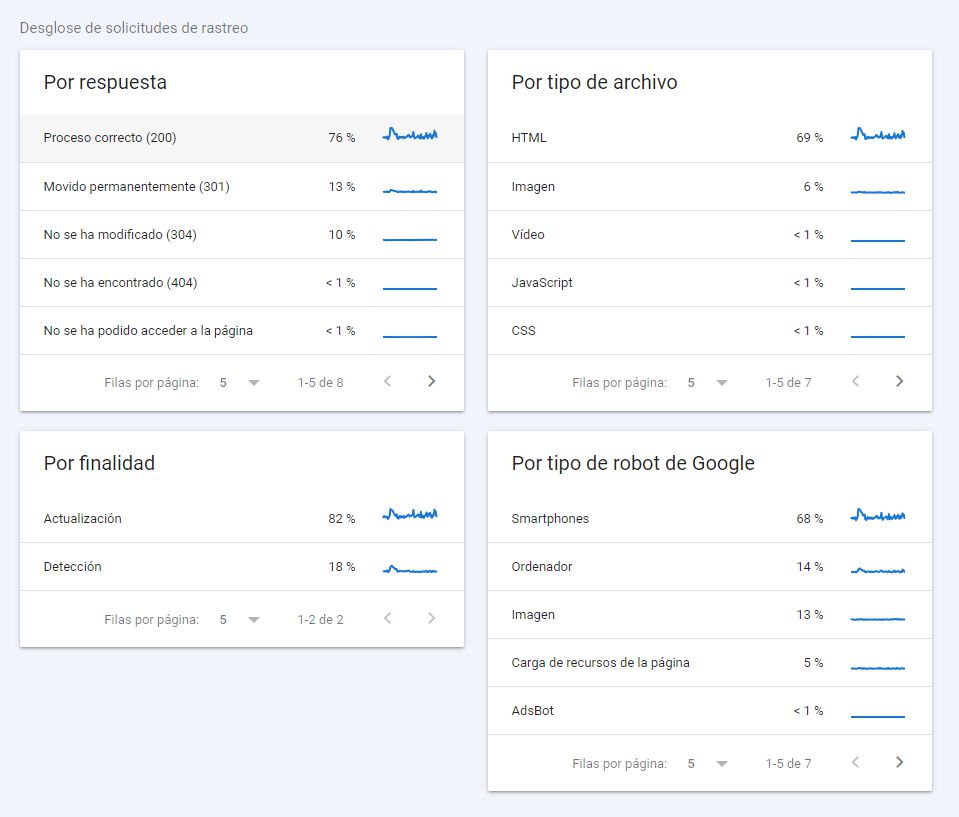
En el desglossament de sol·licituds de rastreig tenim informació molt rellevant:
- Quina resposta de servidor estem entregant (com més 200, millor)
- Per finalitat (renovació o detecció): dependrà de la mida de la nostra web i de la freqüència de publicació i actualització de continguts
- Per tipus de fitxer: l’ideal, atès que estem entregant web, és que en la seva gran majoria detecti HTML. Tot i que això no et passarà amb tecnologies basades en JS, i en aquests casos hauries d’analitzar amb detall els processos de renderització
- Per tipus de robot: el tipus de contingut i la tipologia de dispositius de visita habituals condicionen sovint aquestes dades
Sens dubte, la informació bàsica sobre l’anàlisi de logs ja la podem obtenir a través de l’apartat d’anàlisi de rastreig de Google Search Console.
Per a webs petites això hauria de ser suficient per fer-te una idea de què els passa als bots de Google amb el teu lloc.
Screaming Frog Log Analyzer
Però per a webs grans és molt recomanable monitoritzar els logs, i en aquest cas Search Console es queda molt curt, perquè ens dóna dades limitades, no manipulables i només dels últims 90 dies. Si ets en aquest segon escenari, llavors necessites un programari d’anàlisi de logs que et permeti realitzar una anàlisi en profunditat i una posterior
monitorització del crawling.
Hi ha diverses eines al mercat, però per relació qualitat-preu nosaltres sens dubte et recomanem provar
Screaming Frog Log Analyzer. Si coneixes la granota de Screaming Frog, la seva versió més coneguda el que fa és una simulació de com els bots de Google poden analitzar el nostre lloc. Però amb l’SFLA el que fem és una anàlisi eficient dels logs que s’han produït realment.
Realitzar una anàlisi de logs amb SFLA
En el primer apartat hem definit com obtenir un fitxer de logs. Ara ja tenim aquesta preciositat amb nosaltres, no t’espantis:

Un cop tenim aquest fitxer, l’objectiu serà
filtrar-lo per obtenir només els logs que ens interessen. Aquest procés el podríem fer manualment, però no t’ho recomanem. En aquest exemple farem servir Screaming Frog Log Analyzer. Farem l’exemple amb la versió gratuïta, que agafa una mostra de fins a 1.000 línies. Pugem el fitxer i obtenim una cosa similar a això:
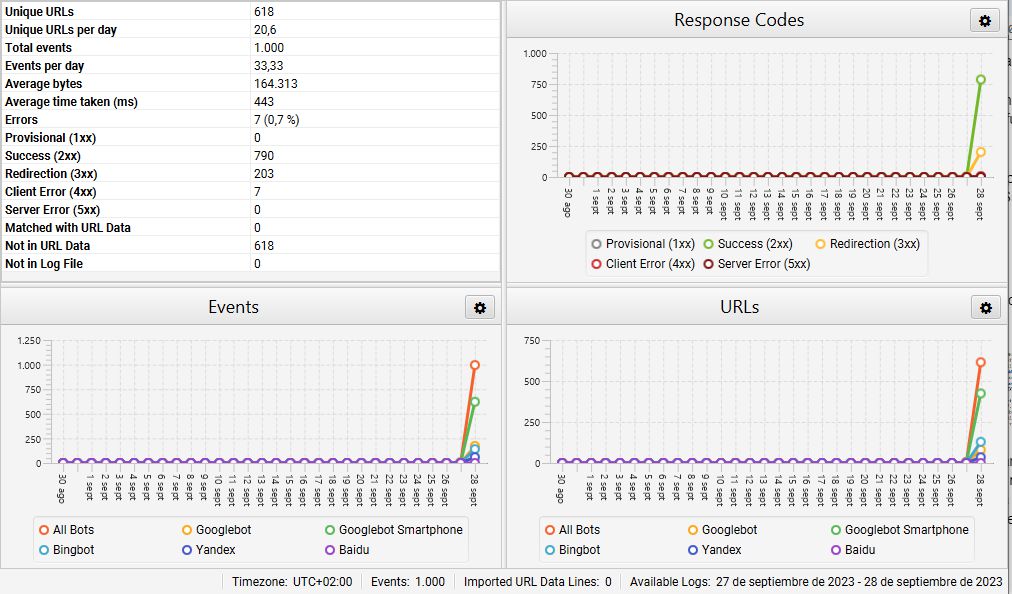
En aquesta primera ullada veiem que dels 1.000 registres la gran majoria són de Googlebot Smartphone i Googlebot (el 80% conjuntament), però compte, també hi ha visites dels bots de Bing, Yandex i Baidu. També obtenim una primera vista de quin codi de resposta estem retornant. Aquest projecte està molt treballat, i no és casualitat que en un 80% dels casos retorni una resposta 200, en un 20% redireccions 3XX i cap resposta 4XX o 5XX, les més nocives.
Però si centrem el nostre focus en Google, l’eina ens permet filtrar les dades només amb les visites dels bots de Google, fins i tot només d’un d’ells:
A més de l’
overview amb dades generals dels logs, ens ofereix diverses pestanyes per anar analitzant les dades segmentades. Al final la informació és la mateixa però agrupada segons diferents paràmetres:
- URLs: les pàgines visitades pel bot, les vegades que s’han visitat, l’últim codi de resposta obtingut o la mida dels fitxers, entre altres
- Response codes: els esdeveniments ordenats per codis de resposta
- User agents
- Referers: ens permet saber quina ha estat la font que ha portat Google a descobrir aquell recurs. Poden ser URLs internes, però també webs externes
- Directories: agrupació del contingut visitat en funció de les carpetes del nostre hosting
- IPs: et recomanem que quan creïs el projecte marquis la casella per verificar només les visites de Googlebot reals i no les simulades. En aquest cas, totes les IP seran de Google (haurien de començar per 66.249).
- Països
- Events: normalment preferiràs veure els esdeveniments agrupats per URLs, però aquí els tens tots
- Importació de dades externes: serveix per si volem pujar altres dades, per exemple un rastreig de l’spider de Screaming Frog, per creuar-lo i comparar-lo amb el rastreig real de Google. Permet trobar URLs òrfenes, per exemple.
Un cop obtenim aquestes dades, és interessant analitzar-les i intentar treure’n conclusions. Hi ha taules senceres que ens poden ser útils i les podem exportar. Algunes suggerències serien:
- Exportar les dades per URLs, ordenar-les per vegades visitades i així creuar el que visita Google amb el que ens interessa que visiti
- Exportar la taula de codis de resposta per aïllar els 4XX, 5XX o fins i tot els 3XX
- Exportar les URLs inconsistents. Millor evitar les de Googlebot Images, perquè donen molts 304 (no modificat), que no són un problema. Una URL inconsistent dóna resultats diferents en diferents logs, amb la qual cosa podríem estar davant de problemes al nostre servidor o al codi
3. Els registres de logs i el SEO
En quins logs ens hem de fixar els SEOs?
Si l’anàlisi de logs l’estàs realitzant per analitzar aspectes relacionats amb el SEO, llavors t’has de fixar essencialment en els logs dels robots de rastreig de Google: Googlebot Smartphone, Googlebot Desktop i Googlebot Images, principalment, tot i que Google va diversificant els bots que utilitza per a l’índex.
Mitjançant l’anàlisi de logs podem saber quins robots visiten el nostre lloc, quines URLs visiten i amb quina freqüència passen per cada URL, entre altra informació interessant.
Informació rellevant a extreure per a SEO en una anàlisi de logs
- Esdeveniments al dia i la seva distribució
- Errors de rastreig
- URLs òrfenes
- Quines parts de la web i quines tipologies d’URLs rastreja més sovint
A partir d’aquesta informació, la processarem i la casarem amb les nostres prioritats de negoci. Imaginem que portem el SEO d’una botiga online, el principal objectiu de la qual és vendre productes a internet, però detectem que els bots visiten sovint pàgines de blog i gairebé mai les de categoria o de producte. Estem davant d’un problema de negoci que hem d’afrontar (vegeu el post
del SEO a quilo al SEO orientat a negoci).
Al final,
l’important és identificar quantes URLs irrellevants està rastrejant i quantes URLs rellevants no està rastrejant prou. El nostre primer objectiu com a SEOs serà aconseguir una distribució eficient del nostre pressupost de rastreig. Perquè no oblidem que el procés de rastreig és previ a la indexació i al posterior posicionament.
Quan realitzar una anàlisi de logs i monitoritzar-los
Anteriorment hem explicat que en una web petita no és necessari realitzar una anàlisi de logs com les descrites en aquest post. És difícil posar-hi una xifra o una mida, però ens atreviríem a dir que
per a webs de menys de 10.000 URLs, amb Search Console en tens de sobres. A partir d’aquí, sí que és interessant realitzar una anàlisi de logs quan obres el projecte i de tant en tant. Per a projectes especialment grans, a més de realitzar una anàlisi inicial, hauries d’establir un protocol de monitorització amb rutines i una periodicitat fixada, encara que dependrà dels recursos disponibles.
L’anàlisi de logs i el crawl budget
Pensa en la quantitat de recursos que ha d’invertir Google per rastrejar milions de pàgines web cada dia. No té recursos il·limitats, així que assigna un temps i mides de descàrrega a cada web. Així doncs, si té 30 segons per registr







Analitzar quins fitxers consulten els robots de Google al nostre web és una pràctica essencial de SEO per a projectes grans.