El bot de indexación de Google es incansable, y su seguimiento y conocimiento nos será clave para nuestro
posicionamiento SEO. En prácticamente un solo día podemos incorporar un nuevo sitio web a su índice si hacemos las cosas correctamente. Pero,
¿y si lo que queremos es eliminar una URL de dicho índice?En ocasiones, la fiabilidad de la araña de rastreo del buscador puede actuar en nuestra contra, añadiendo páginas al índice de Google que no queremos que aparezcan entre los resultados de búsqueda, como por ejemplo un artículo publicado con un enlace erróneo, un e-commerce que genera infinitas URLs debido a los filtros del catálogo, o un sitio web en desarrollo.
¿Qué podemos hacer ante estas situaciones? Vamos a ver las
diferentes opciones que tenemos para desindexar una URL de Google.
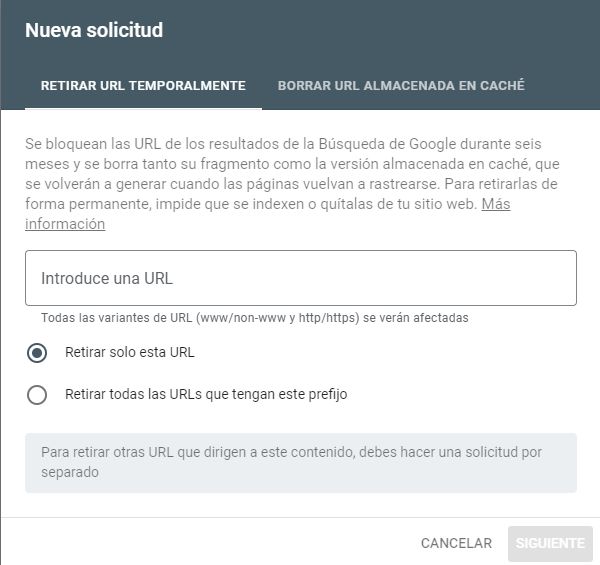
Herramienta Retirada de URLs de Search Console
Google ofrece en su
herramienta para webmasters Google Search Console una opción para
eliminar URLs del índice de su propio buscador. Encontraréis la opción bajo el menú "Índice" de Google. En ella, podréis introducir URLs de una en una y escoger si queréis eliminarlas de los resultados de búsqueda, de la caché o ambas cosas. Además, incluye la posibilidad de eliminar todas las páginas bajo un mismo directorio o un dominio completo.
Una vez enviéis una dirección, esta pasará al estado "Pendiente". En unas pocas horas, si todo va bien, su estado pasará a "Eliminada". También cabe la posibilidad de que os denieguen este cambio, aunque no es habitual. Una vez eliminada, tendréis la opción de revertir los cambios por si hubieseis eliminado alguna página por error.
Etiqueta Meta Robots con valor noindex
La incorporación de la
etiqueta Meta Robots al código HTML de una página con el valor noindex nos permite indicar a los buscadores, entre ellos Google, que esta no debe ser indexada. Al tratarse de una indicación de tipo directiva, Google debería eliminar dicha página de su índice (o no incorporarla si aún no la había detectado).
Dicha directiva también puede implementarse a través de la cabecera HTTP X-Robots-Tag.
Etiqueta Canonical
Si la página que queremos eliminar del índice corresponde a un duplicado o variación de una URL existente, podemos utilizar la
etiqueta Canonical para eliminar la versión que no nos interese indexar.
A diferencia del caso anterior, la etiqueta Canonical no es una directiva, por lo que Google puede optar por ignorarla, pero le va a dar pistas de qué URLs son buenas. Además, su función original no está directamente vinculada a eliminar URLs del índice. También podemos implementarla a través de cabeceras HTTP.
Disallow en robots.txt
En este caso se trata de una
medida preventiva, que no nos servirá para eliminar páginas del índice, pero nos permitirá evitar que futuras URLs se indexen. En el
archivo robots.txt podemos especificar que el bot de Google no acceda a ciertas páginas, carpetas, rutas, tipos de archivo, etc., haciendo que sea incapaz de incorporarlas al índice. Esto sólo vale si las URLs que no queremos no se han indexado. Si de lo contrario ya han pasado, primero debes desindexarlas con los métodos anteriores, y después bloquearlas con la directiva Disallow.
Códigos de respuesta HTTP
Algunos
códigos de respuesta HTTP pueden, a la larga, provocando la desindexación de una URL concreta. Una página redirigida mediante un código 301 o que presente un código de error 410, indican a Google que ha habido un cambio permanente en la URL.
Otras formas
Existen otros mecanismos que pueden provocar la desindexación de una URL, pero estos son los más comunes y que pueden producir efectos más inmediatos,
principalmente la herramienta de Eliminar URLs de Google y la etiqueta Meta Robots con el valor noindex. Si tenéis alguna duda en relación a la indexación de Google o cualquier otra cuestión relacionada con el posicionamiento SEO, no dudéis en contactar con nosotros.
Errores comunes al desindexar
A continuación te mencionamos los errores más comunes al querer desindexar una página de tu web, son los siguientes:
- Usar solo Disallow en robots.txt sin noindex.
- Eliminar la página del servidor sin redirección ni código 410.
- Confundir desindexar con eliminar del servidor.
- No revisar si Google sigue mostrando la URL tras varios días.
¿Cómo saber qué URLs se deben desindexar de tu web?
Antes de ponerte a desindexar páginas de tu sitio web en Google, es conveniente analizar qué páginas te están restando valor. A continuación te exponemos las formas más habituales de poder detectarlo:
A través de Google Search Console
En el apartado de indexación, dentro de la herramienta, podrás detectar aquellas URLs que están indexadas, excluidas o con errores. Además, Search Console te da avisos de páginas “Duplicadas sin etiqueta canonical” o “Rastreadas sin indexar”. A través de estos listados puedes empezar a clasificar URLs con poco valor que están indexadas, incluso lo contrario, alguna página importante de tu web que todavía no ha indexado.
Google Analytics
Google Analytics también puede ser una herramienta muy útil para identificar URLs sin visitas o con un alto porcentaje de rebote. Por estos motivos, si esas páginas no generan tráfico ni conversiones y tampoco aportan valor a la web, pueden ser candidatas para forzarse una desindexación
Con Screaming Frog
A través de herramientas como Screaming Frog puedes detectar páginas huérfanas, duplicadas, sin enlaces internos o, incluso, con poco contenido. Todas estas propiedades que mencionamos que puede tener cualquier página de tu web son claves para poder decidir si es conveniente su desindexación.
Herramientas como Ahrefs, SemRush, DinoRank…
Este tipo de herramientas también te pueden ayudar a detectar aquellas páginas poco relevantes de tu web, contenidos que se canibalizan, etc.
Toda la información que puedas extraer a través de estas herramientas es clave para tomar la decisión de desindexar una URL de tu sitio web. Como se ha mencionado, aspectos como páginas con poco contenido y valor, posibles duplicados, páginas que generan URLs infinitas… son motivos para intentar desindexar de Google.
Preguntas frecuentes sobre desindexación
¿Cuánto tarda Google en desindexar una URL?
Varía según la frecuencia de rastreo del sitio. Normalmente entre 1 y 15 días.
¿Una URL desindexada puede volver a aparecer en Google?
Sí, si no aplicas correctamente las etiquetas noindex, redirecciones o cabeceras adecuadas.
¿Qué método es el más recomendable?
Depende del caso. Si es una página obsoleta, el noindex o una redirección suelen ser la mejor opción. Para contenido sensible, Search Console es más rápido.
¿Aplicar desindexaciones afectará negativamente al posicionamiento SEO general de la web?
No, si la desindexación tiene sentido dentro de la web. El hecho de desindexar una URL que está duplicada, que ofrece contenido de baja calidad o que genera problemas de rastreo, ayudará a mejorar la calidad general de la web a ojos de Google.
¿Se debe eliminar la URL del sitemap de la web tras desindexarla?
Sí, lo más correcto sería eliminar la URL del sitemap, ya que la función principal de este archivo es mostrar a Google qué URLs debe rastrear e indexar de tu web.